As the field of artificial intelligence continues to make significant strides, the need to customize large language models (LLMs) for specific applications is becoming increasingly apparent. Two primary approaches that have emerged are fine-tuning and in-context learning (ICL). Each presents its own set of advantages and challenges. A recent investigation by researchers from Google DeepMind and Stanford University has provided fresh insights into how these techniques can be leveraged effectively for optimal performance in complex tasks. By examining their generalization capabilities, the research reveals not only the strengths but also the weaknesses of each approach as we endeavor to unlock the full potential of LLMs in real-world applications.
Fine-Tuning: A Deep Dive into Model Customization
Fine-tuning is a well-established method wherein a pre-trained LLM is further trained on a more specialized dataset, allowing it to adapt and learn new knowledge or skills that are specific to a particular domain. The process involves adjusting the internal parameters of the model, which can be time-consuming and resource-intensive. Although fine-tuning offers the advantage of a tailored model that performs impressively on the specific tasks it was trained on, the pitfalls of this approach lie in its potential for overfitting or underperforming on non-matching queries. Is fine-tuning too rigid for the unpredictable nature of real-world data?
In contrast, ICL presents a more agile solution. Instead of altering the model’s parameters, ICL functions by providing the model with prompts directly aligned with the expected outcomes. This method enables the model to demonstrate spontaneity and flexibility, as it selects relevant examples from the input to address new queries. In doing so, ICL sheds light on the importance of contextual awareness without the heavy lifting associated with fine-tuning. However, this flexibility comes at a cost—specifically, higher computational demands during each instance of inference.
Finding the Balance: The Strengths of In-Context Learning
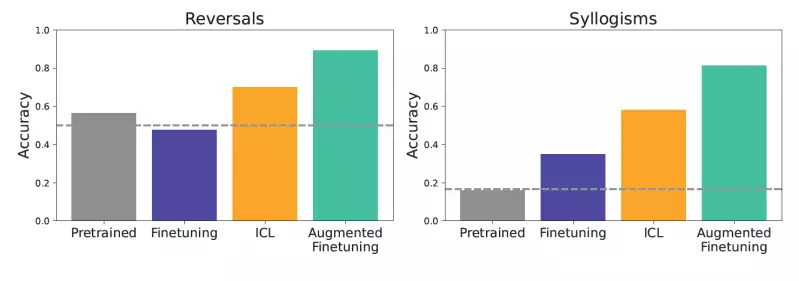
The research led by Lampinen and his team highlights a significant nuance: ICL’s superior generalization capability compared to conventional fine-tuning, particularly in diverse task scenarios. The study rigorously tested these methodologies against carefully constructed synthetic datasets, which ensured clarity in assessing model performance, free from prior exposure the models had during their pre-training phase. The tests included relationship reversals and syllogisms, evaluating the models’ ability to draw logical deductions from newly introduced information. The results overwhelmingly favored ICL for their generalization prowess, demonstrating that LLMs utilizing this method could tackle complex relationships and reasoning tasks more effectively than those relying solely on fine-tuning.
These findings lead to a hypothesis: that ICL’s capacity for flexible reasoning could be supplemented to enhance fine-tuning processes. Emerging from this insight is a novel approach called augmented fine-tuning, which leverages ICL’s own aptitude to infer and generate diverse examples while fine-tuning. The promise here lies in the potential to fuse the strengths of both techniques, creating models that not only adapt to specific datasets but can also generalize across varied tasks seamlessly.
Augmented Fine-Tuning: The Game Changer
Augmented fine-tuning represents a transformative step forward, wherein models are not merely conditioned by the data they are fine-tuned on but are, in essence, revitalized by it. This approach incorporates two primary strategies: a local strategy that focuses on inferring information within individual pieces of data, and a global strategy that introduces broader contextual insights drawn from extensive datasets. By employing these diverse strategies, the models trained on these ICL-augmented datasets are not just improved to handle more varied inputs but also demonstrate a remarkable ability to generalize their responses.
Moreover, this innovative method alleviates one significant criticism of ICL—the computational burden associated with continuous large-context prompts. While augmented fine-tuning does introduce additional computational complexity during the training phase, it provides lasting benefits during inference. Essentially, organizations investing in this method could find that the upfront costs are outweighed by the long-term advantages of having a model that operates efficiently on a variety of tasks, thus enhancing productivity and performance.
The Future of Language Model Applications
As firms increasingly turn to LLMs for enterprise solutions, the implications of this research cannot be understated. The insights offered by the study underscore the importance of adaptability in LLM usage, especially in rapidly changing environments where data evolves continuously. By investing in creating datasets enriched with ICL capabilities, enterprises stand to gain significant advantages in deploying models that are not just proficiently fine-tuned but also remarkably versatile.
The research opens a dialogue about not only the future designs of LLMs but also the strategic considerations enterprises must take into account when choosing their approach. As Lampinen aptly notes, the question remains whether the added cost of augmented fine-tuning is justified by the contextual richness and generalization capabilities it proffers compared to traditional methods. Nevertheless, the pursuit of understanding how to best adapt and optimize these models signals an exciting new chapter in the realm of artificial intelligence. The dynamic interplay between fine-tuning and ICL represents a pathway toward more robust, reliable applications that will ultimately shape the future of language technology.